4008-588-669
发布日期:2020-06-03 来源:《中台战略》

数据模型是数据中台中数字资产的重要组成部分,一个完整、灵活、稳定的数据模型对于项目的成功起着至关重要的作用。
数据模型是整个系统建设过程的导航图。通过数据模型可以清楚地表达企业内部各种业务主体之间的相关性,使不同部门的业务人员、应用开发人员和系统管理人员获得关于系统的统一完整的视图。
数据模型有利于数据的整合。数据模型是整合各种数据源的重要手段,通过数据模型,可以建立起各个业务系统与数据库之间的映射关系,实现源数据的有效采集。
通过建立数据模型,可以排除数据描述的不一致性,如同名异义、同物异名等,使系统的各参与方能够基于相同的事实进行有效沟通。比如,通过ID-Mapping实现不同系统中同一消费者的识别。
数据模型可以消除数据库中的冗余数据。数据模型的建立可以使开发人员清楚地了解数据之间的关系,以及数据的作用。在数据库中根据需求采集那些用于分析的数据,而不需要那些纯粹用于操作的数据。
数据模型具体分为分析模型与应用算法模型两大类。分析模型是数据中台的重要数据资产。简单来讲,分析模型就是将企业全域的数据按照主题域进行梳理,并按照数据的粗细粒度进行分层存储,供上层数据应用按需索取。
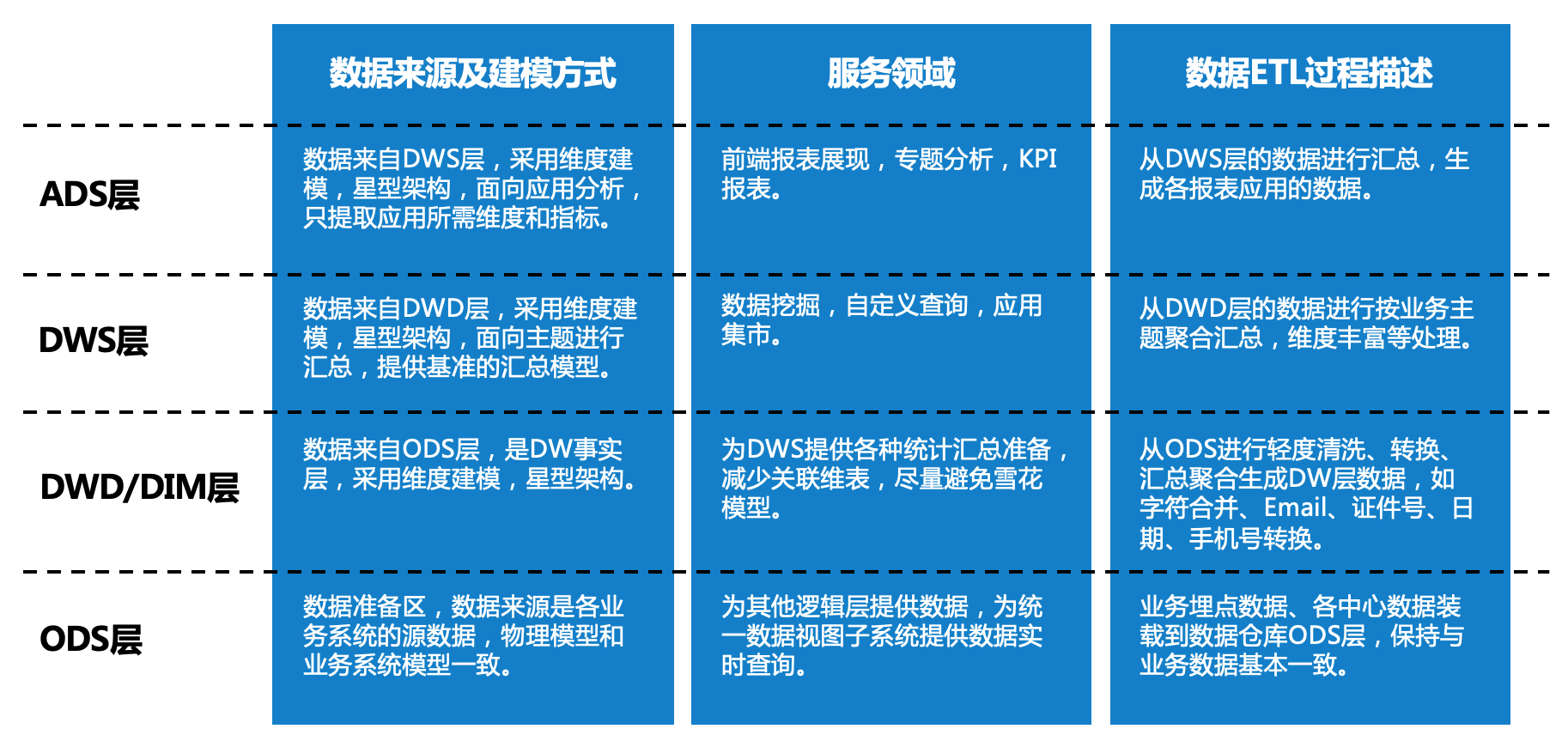
企业在搭建数据中台时应如何建设分析模型呢?建议从企业整体业务出发,梳理全量业务进行分层建模,将数据按照功能性、量级分为四层(见下图):ODS层(操作性数据)、DWD层(明细宽表级数据)、DWS层(公共汇总数据)、ADS层(专业应用汇总数据)。一般来讲,DWD和DWS两层又合称为中间层,是整个分析模型的核心和灵魂。
分层建模整体逻辑
ODS是“面向主题的、集成的、当前或接近当前的、不断变化的”数据,是分析模型中的一个可选部分,ODS具备数据分析的部分特征和OLTP系统的部分特征。
数据聚合:将来自不同系统的同类数据源按照某种维度进行聚合,形成统一的聚合数据。例如,对某用户在某时段在京东、天猫的订单进行聚合,形成宽表。
丰富维度:将事实表与维度表进行充分关联聚合后,丰富事实表的维度,避免数据在后续计算时需要关联大量的维度表,将雪花模型转换为星型模型。例如,订单表中存在商品编码,通过商品编码与商品维表的关联,将商品类别、商品规格、商品单价等属性值写入事实表。
维度退化:加强指标的维度退化,提炼出粗粒度的常用维度、常用指标的汇总模型;数据汇总程度高于DWD层,单表数据量明显减少,通常采用星型建模。
形成主题宽表:根据客户、商品、经销商、店铺等实体在某一段时间内的事件轨迹,串联起整体业务,形成全方位的公共基础宽表,通常采用实体建模。例如客户实体,可以通过客户基本属性、客户购物经历、购物偏好、金融风险评级等维度360°全方位形成客户宽表。
以上两种手段旨在提升公共指标的复用性,减少重复的加工工作。
个性化指标加工:无公用性、复杂性(指数型、比值型、排名型指标),通过DWS层的公共基础指标衍生出应用型的衍生指标。
基于应用的数据组装:大宽表集市、横表转纵表、趋势指标串等应用型数据。
谈到算法,很多人就会想到数据挖掘中的算法,比如:决策树、逻辑回归、神经网络等,但这里讲的算法模型是从数据应用场景出发,不重点讲算法如何实现,主要讲述围绕营销、运营、客服等场景如何利用这些算法封装出标准的算法模型,供前端应用场景调用。应用算法模型是数据中台中的高价值资产,真正体现数据中台与传统数据仓库差异的根本点,有了能贴近应用场景的高度抽象的算法模型才能实现数据中台的价值。当然,在建设算法模型的时候切忌为了建模型而建模型,一定要从数据应用场景出发。一般来说,企业围绕营销闭环存在较多的算法模型需求,且解决这些场景的算法模型也比较丰富多样,下面介绍几个最常用的算法模型。
交叉销售这个概念在传统行业里其实已经非常成熟了,也已被普遍应用。其背后的理论依据是一旦客户购买了某一种商品后,企业会想方设法留住并延长这些客户的留存时间,增加客户购买商品的连带率。考虑到企业的生命周期和客户的利润贡献,一般会有两个运营选择方向:一是延缓客户流失,让客户尽可能长久地留存,常用的方法是利用客户流失预警模型提前锁定可能流失的有价值的用户,然后由客户服务团队采用各种客户关怀措施,尽可能挽留客户,从而降低客户流失率;二是让客户消费更多的商品和服务,从而更大地提升客户的商业价值,挖掘客户利润,一般是通过数据算法模型找出客户进一步的消费需求(潜在需求),从而更好及更主动地引导、满足、迎合客户需求,既可提高企业的GMV,又为客户提供更友好的购物体验。
交叉销售模型是指通过对用户历史消费数据的分析挖掘,找出有明显关联性质的商品组合,然后用不同的建模方法,去构建消费者购买这些关联商品组合的可能模型,再用其中优秀的模型去预测新客户购买特定商品组合的可能性。这里的商品组合可以是同时购买,也可以有先后顺序,不可一概而论,关键要看具体的业务场景和业务背景。比如线下门店可根据交叉营销模型推荐的商品组合在货架上进行关联的商品摆放;在线上的商城则可以在“猜你喜欢”“买了再买”这些专栏上提供相关的商品展示。
不同的交叉销售模型有不同的思路和不同的建模技术,但前提都是通过数据探索找出有明显意义和商业价值的商品组合,可以同时购买,也可以有先后顺序,然后根据找出的这些特性去建设算法模型。
实现交叉营销模型的算法有很多,其具体实现原理不是本书讲解的重点,这里不再叙述。这里主要讲解常用的几类算法:一是按照关联规则算法,也即通常所说的购物篮分析,发现那些有较大可能被一起采购的商品,对它们进行有针对性的促销和捆绑,这就是交叉销售;二是借鉴响应模型的思路,为某几种重要商品分别建立预测模型,对潜在消费者通过这些特定预测模型进行过滤,然后针对最有可能的前*% 的消费者进行精确的营销触达;三是仍然借鉴预测响应模型的思路,让重要商品两两组合,找出那些最有可能消费的潜在客户;四是通过决策树清晰的树状规则,发现基于具体数据资源的具体规则逐层判断客户会对哪几种潜在的商品感兴趣。
相应的建模技术主要包括关联分析(Association Analysis)、序列分析(Sequence Analysis)以及逻辑回归、决策树等算法。
信用风险包括欺诈预警、交易风控、反刷单等在交易场景下的风险预警,风险预警在企业特别是金融行业有着举足轻重的作用。互联网公司获客最常用的方式是补贴,但补贴最怕“羊毛党”。如何从海量用户中识别出正常用户,是互联网行业普遍遇到的难题。那么信用风险模型具体是如何实现的呢?
以反刷单模型来讲,一般会选择规则归纳算法,通过正、反双向的历史数据进行训练,从用户的注册时间、注册频次、下单频次、行为模式等这些输入因子进行规则分类,按照规则判断出可疑性较强的客户并提供给前端,禁止其注册、购买等手段,保障资源不流失。
推荐模型是互联网模式下使用的最广泛的算法模型,淘宝首页上的千人一面、千人十面到千人千面这样的个性化展示均是依赖于商品推荐模型。强大的商品推荐模型可以洞悉客户最关注的商品,最有可能购买的商品。据阿里巴巴内部统计,自淘宝网实现“千人千面”功能以来,从首页带来的流量远高于从搜索页面过来的流量。
电商推荐系统主要通过统计和机器学习技术,并根据用户在各端的行为,主动为用户提供推荐服务,从而提高网站体验。根据不同的商业需求,电商推荐系统需要满足不同的推荐粒度,主要以商品推荐为主,但是还有一些其他粒度推荐。譬如查询推荐、商品类目推荐、商品标签推荐、店铺推荐等。目前,常用的商品推荐模型主要分为规则模型、协同过滤和基于内容的推荐模型。不同的推荐模型有不同的推荐算法,譬如规则模型,常用的算法有Apriori,而协同过滤中则涉及kmeans最近邻居算法、因子模型等。没有放之四海而皆准的算法,在不同的电商产品中,在不同的电商业务场景中,需要的算法也是不一样的。实际上,由于每种算法各有优缺点,因此往往需要混合多种算法,取长补短,从而提高算法的精准性。
在全渠道一体化的新零售模式大行其道的今天,对于零售企业,除了在营销端需要算法模型支撑基于大数据的智慧营销之外,在供应链端更需要通过算法模型对历史积淀下来的海量销售数据、铺货经验、补货记录、调拨记录进行分析以提供更加精准的铺、补、调货决策。通过供应方式(供应时间,供应数量,供应周期等)的决策达到仓库中需求和供给的平衡,使得仓库中货品的库存既可以最大化满足用户的需求,也能将库存周转时间控制在一定范围之内,保证供应的效率。
智能配补货模型实现的难点是如何精准预测某一段时间区域、门店甚至某一款商品SKU的销量,而销量预测的难度又在于除了历史的销量、促销活动、行业动态之外还有很多主观影响因素,如天气变化、国家政策等不可抗力因素。下图为基于销量预测的智能补货算法模型实现逻辑。

 云徙科技官方公众号
云徙科技官方公众号
 88号实验室
88号实验室
Copyright © 2019 云徙科技有限公司All Rights Reserved 浙ICP备16028793号 备案号33010802007501
备案号33010802007501
市场合作:zhao.jing@dtyunxi.com媒体合作:markting@dtyunxi.com





 在线
在线
 联系
联系
 申请
申请
 返回
返回